How We Use Philter Scope to Evaluate Our PII Models
A PII model is only as trustworthy as its measurements. The way to know whether one finds what it should is to score it against a labeled gold standard: precision (how much of what it flagged was correct) and recall (how much of what it should have flagged it caught). That scoring is what Philter Scope does, and it is how we evaluate the models we train. Here is the workflow, using the three ph-eye-pii-en name models (the how and why is here ) as the worked example.
Our models on Hugging Face
We recently published three open person-name detection models on Hugging Face: ph-eye-pii-en-small, ph-eye-pii-en-medium, and ph-eye-pii-en-large. They are English name detectors, built by fine-tuning GLiNER on NVIDIA’s Nemotron-PII dataset and released under CC-BY-4.0, and they come in three sizes so you can trade accuracy against latency and footprint. They are served by PhEye and drop straight into Philter , or you can run them on their own. For what they detect, how they were trained, and the design decisions behind them, see How We Built PhEye’s PII Name Models .
Publishing the weights is only half the work. Training produces a model; evaluation tells you whether you can trust it. A name detector you have not measured is one you cannot stand behind, so we treat evaluating a model as just as important as training it. The rest of this post is how we do that with Philter Scope.
Why measuring matters
You cannot manage what you do not measure, and redaction is a place where not measuring is genuinely risky. A model that looks like it is working can be quietly missing names in exactly the documents that matter, and you would not catch it by eyeballing a few examples. The cost of a miss is concrete: one leaked name in a discovery production, a clinical note, or a support transcript can become a privacy incident, a compliance failure, or a breach notification.
Two numbers tell you where you stand. Recall is how much of the sensitive data the model caught, so low recall means leaks. Precision is how much of what it flagged was actually sensitive, so low precision means over-redaction that strips the usefulness out of a document. The right balance between them is not universal; it depends on your data and your tolerance for each kind of error. The only way to know your numbers, on your documents, is to score them against a gold standard, and that is the work Philter Scope makes routine.
Why recall?
For most redaction work, recall is the number to optimize first. The two errors are not symmetric. A missed name is sensitive data that escaped, which can mean a privacy incident, a regulatory violation, or a breach notification, and you cannot take it back. An extra redaction is a word blacked out that did not need to be, which is over-redaction you can loosen later by tuning the policy. When the cost of a miss is that lopsided, you would rather catch every name and accept some over-redaction than run leaner and let one through, which is why our name models are tuned to lean toward recall. It is not universal: in workloads where over-redaction destroys the value of the document and the regulatory exposure is low, precision matters more. That is the whole reason to measure both on your own data and choose the balance your risk calls for.
How Philter Scope evaluates a model
Philter Scope compares two things span by span: the gold-standard labels for a set of documents, and the detections a model produced over those same documents. From the overlaps it computes precision, recall, and F1, overall and per entity type, plus a confusion matrix, and renders them in a dashboard. It can score Philter’s live output, or detections you have already computed, which means you can hand it any model’s predictions without standing up a server.
That is the whole idea: point Philter Scope at a gold standard and a set of detections, and it tells you, in the terms that matter for redaction, how good those detections are. And because it is open source, you can read exactly how every number is computed, trust the result, and run it wherever your data lives, including fully offline inside your own boundary.
Evaluating our own models
The recipe has three inputs:
- A gold standard: the held-out test split of NVIDIA’s Nemotron-PII, with the name spans labeled.
- Predictions: each model run over those documents at its recommended confidence threshold.
- The score: hand both to Philter Scope.
We ran all three sizes this way, names only, across 1,246 test windows.
| Model | Threshold | Precision | Recall | F1 |
|---|---|---|---|---|
| ph-eye-pii-en-small | 0.90 | 0.976 | 0.998 | 0.987 |
| ph-eye-pii-en-medium | 0.70 | 0.968 | 0.998 | 0.983 |
| ph-eye-pii-en-large | 0.95 | 0.975 | 0.997 | 0.986 |
Evaluating the results
Each run produces a Philter Scope dashboard: the three headline numbers, a per-entity recall bar with a pass or fail status, and a confusion matrix that counts how many names were caught, missed, or wrongly flagged. Read each one starting with recall, because in redaction a missed name is a leak. The threshold shown on each dashboard is Philter Scope’s pass/fail recall target; the model’s own confidence threshold was applied when its predictions were generated. (Screenshots may not reflect the current version.)
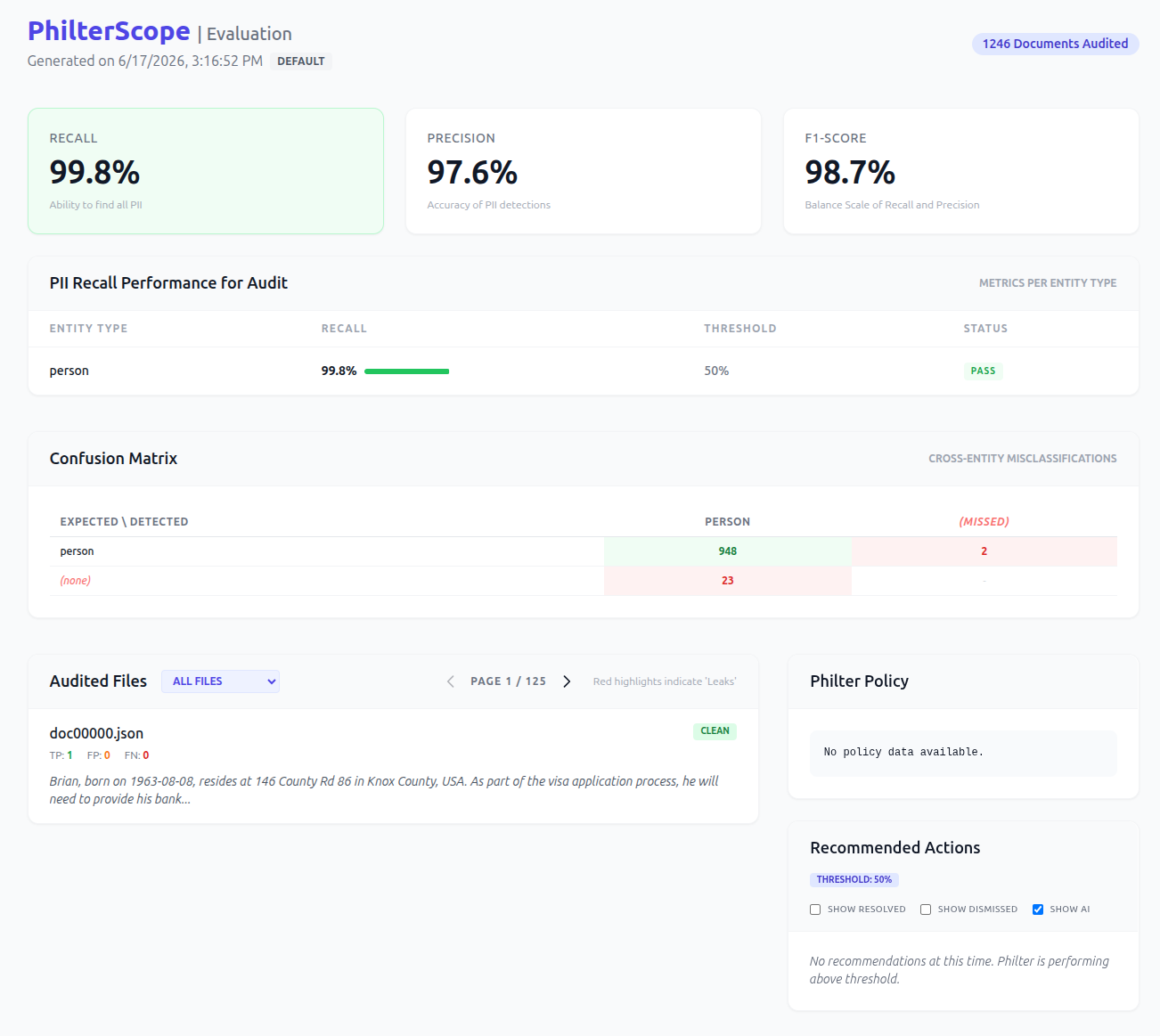
The small model finds 948 of the 950 names in the sample and misses 2, which is the 99.8% recall shown at the top. At its recommended threshold it leaked two names across 1,246 documents. Precision is 97.6%: of everything it flagged, 23 spans were not gold names, so it over-redacts a little rather than leaking. The F1 of 98.7% balances the two. For the smallest and fastest model in the family, catching all but two names is a strong result, and the recall check passes.
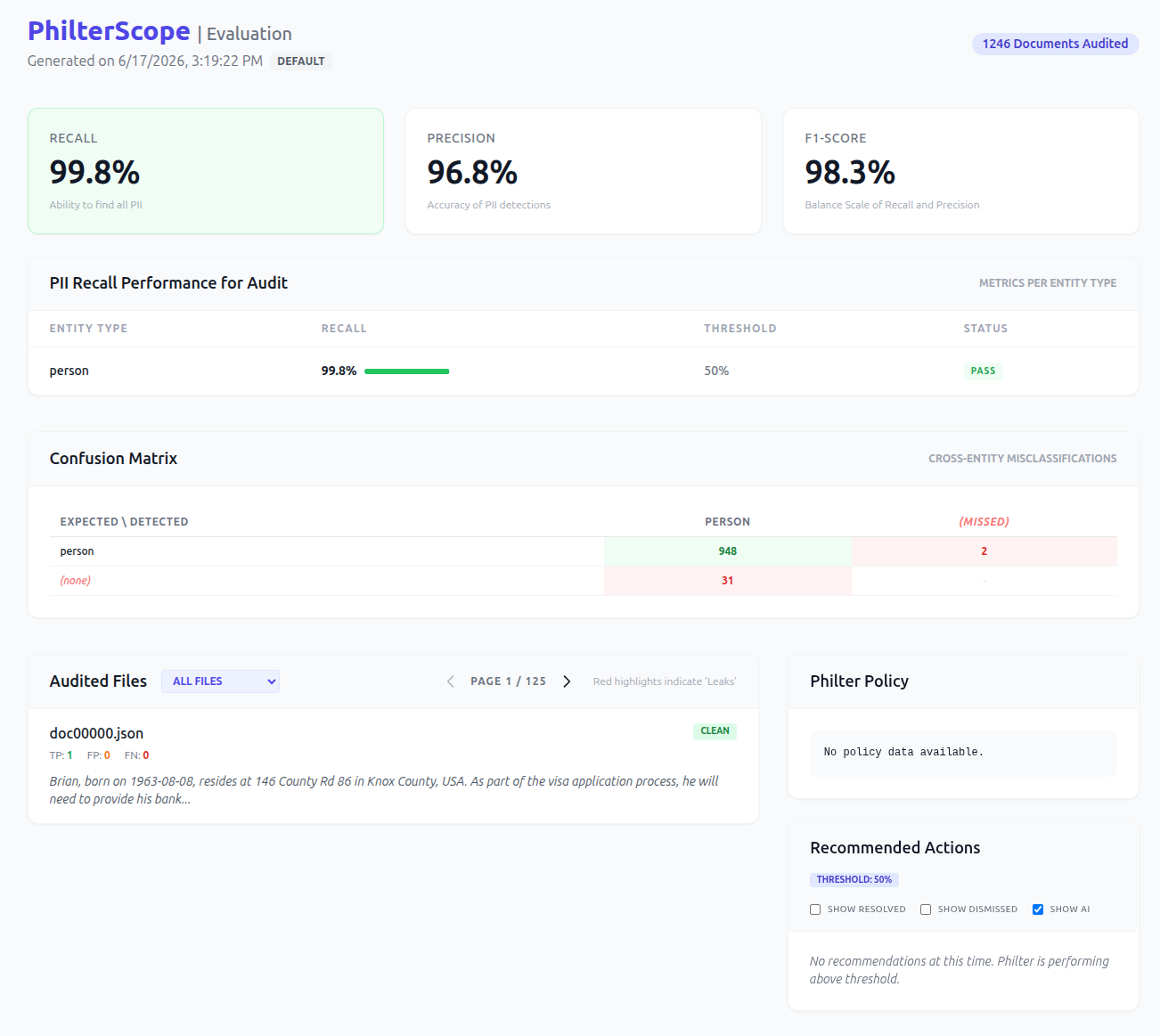
The medium model lands in the same place on recall: 948 of 950 names found, 2 missed, 99.8%. Its precision is slightly lower at 96.8% (31 stray spans instead of 23), so at its lower recommended threshold of 0.70 it over-redacts a bit more than the small model does at 0.90. Each model is shown at its own recommended operating point, so this is not a like-for-like comparison; it is each model where we suggest running it. The F1 is 98.3%.
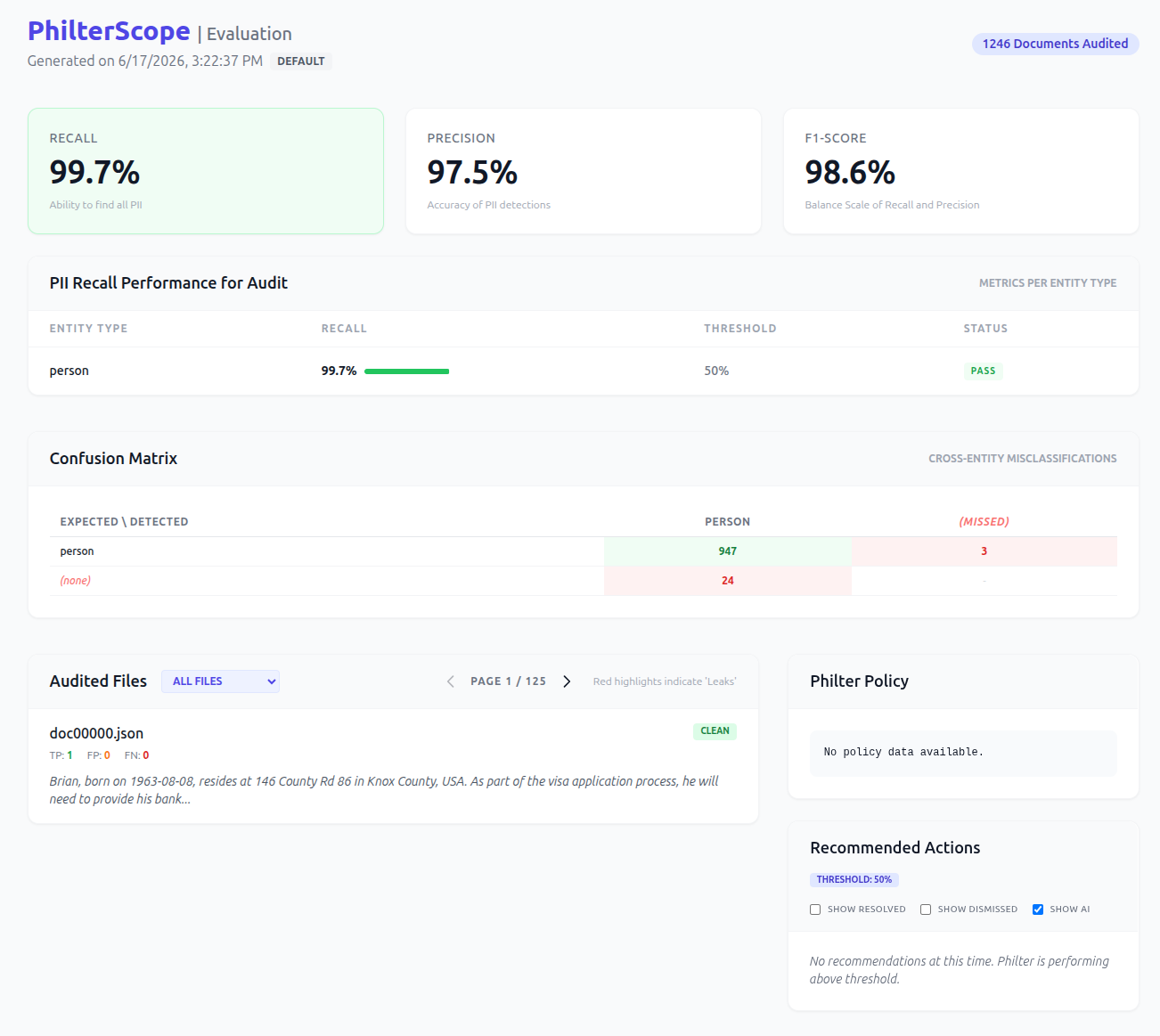
The large model catches 947 of 950 and misses 3, for 99.7% recall, with 97.5% precision (24 stray spans) and a 98.6% F1. The largest model does not top the chart here: at these operating points all three are within a fraction of a point of each other, and the small model slightly edges them on F1. Bigger is not automatically better for a task this narrow, and that is exactly the kind of thing you only learn by measuring. All three pass.
Across all three, recall holds at about 99.8% and precision stays in the high 0.96 to 0.98 range. These numbers line up with the published model cards, which is the result we wanted: a model evaluated through our own auditing tool reproduces the numbers we report. For what these models are, how they were trained, and what these numbers do and do not tell you, see How We Built PhEye’s PII Name Models .
Run it on your own data
The real value of this workflow is that you can run it on your own data. Philter Scope is open source on GitHub and scores any detections against any gold standard. Point it at your documents, your labels, and your policy, and you get the same precision and recall view for your distribution instead of ours. Measuring redaction on your own data is the only way to actually know how it performs, and making that routine is why the tool exists.
Try it
- The models: small, medium, large.
- Philter Scope on GitHub, and the Philter Scope product page .
- Where these models fit in an end-to-end redaction pipeline: Philter and PhEye .
Need this for your own data?
Training a model for a domain we do not ship yet, or rigorously evaluating redaction against your own gold standard, is work we do. If you have a PII or PHI redaction workload that needs a custom model, a tuned policy, or a precision and recall evaluation on your own sensitive data, we can help you build it and prove it works.