How to Tell if a PII Redaction Model Is Any Good
It has become common to advertise a model catalog by its size. Hundreds of checkpoints, sometimes thousands, listed as if the count were the achievement. For PII redaction in particular, that number tells you almost nothing about whether any single model will catch the names in your documents.
A large catalog is usually not a large amount of work. One training pipeline, run across a matrix of task by encoder by language, produces a lot of artifacts from a little effort. The count grows with the size of the matrix, not with the care taken on any one model. The question that matters is not how many models a project ships. It is whether the one you are about to deploy has been measured, on data it did not see during training, in terms that map to the cost of being wrong.
This post is about what that measurement looks like, and we will use our own English name model as the worked example, including the numbers that are not flattering.
What “good” actually requires
A redaction model is good when you can answer four questions about it with evidence.
Was it measured on data it did not train on? A score on the training data measures memorization, not skill. The only number worth reporting comes from a held-out split the model never saw, scored per task and per language rather than blended into one figure that hides where the model is weak.
Were precision and recall reported, not just F1? F1 is a single number that averages two very different failure modes. For redaction those modes are not equally costly. Missing a name is a leak; flagging an extra span is over-redaction you can loosen later. A model tuned to look good on F1 can be quietly trading away the recall you actually need. The honest report shows both numbers and says which one was optimized.
Was span matching defined? “The model found the name” can mean the predicted span matched the gold span exactly, or only overlapped it. Exact matching is stricter and the more conservative number to publish. Overlap matching is more forgiving. A result is not interpretable unless it says which rule produced it, and ideally reports both.
Can an auditor read the card? A model card that lists the base model, the training data and its license, the evaluation split, the threshold, and the resulting precision and recall is something a buyer in a regulated setting can actually check. A card that lists only a benchmark badge is not.
None of this requires a large catalog. It requires that each model arrives with its receipts.
A worked example, with our own numbers
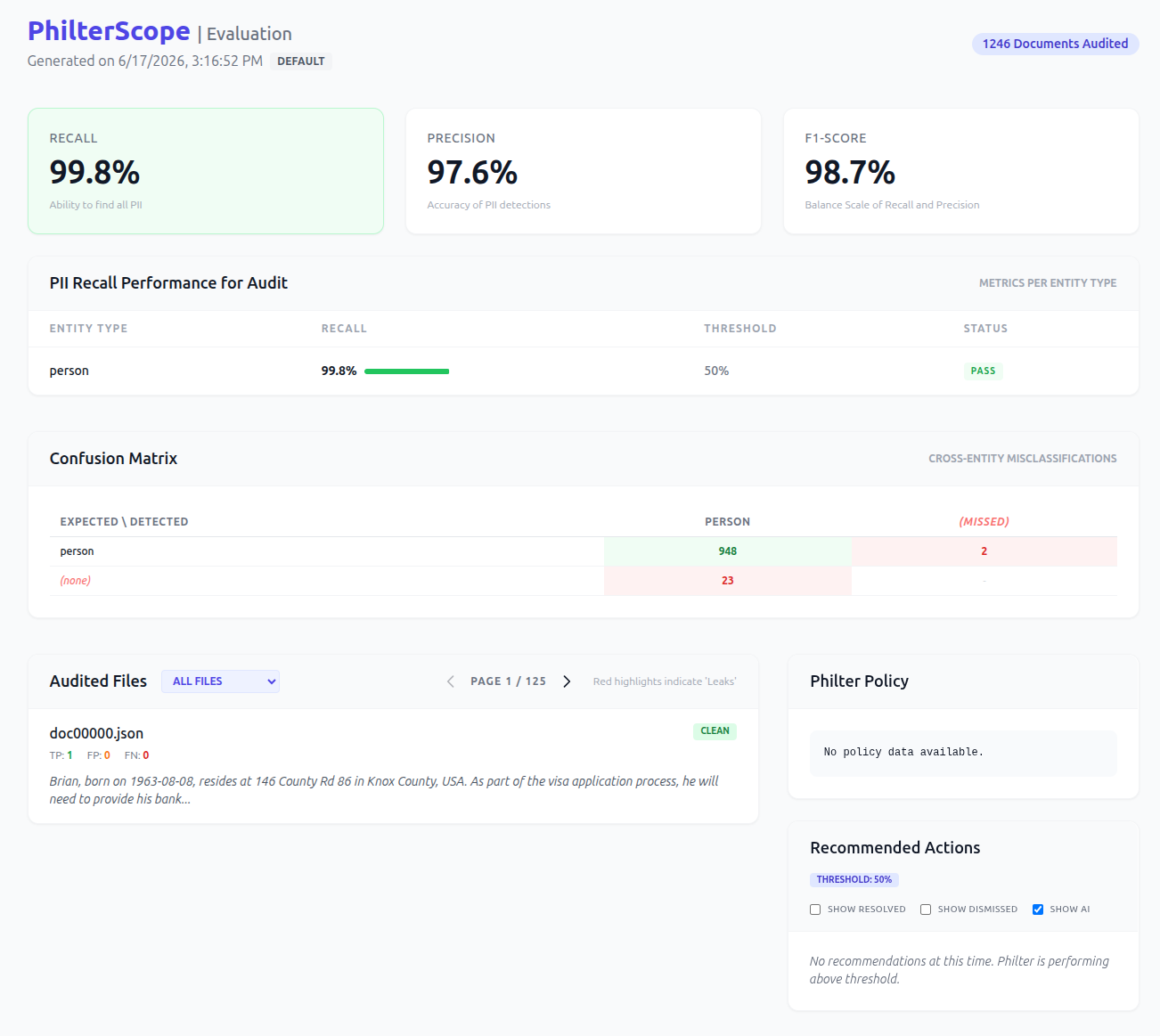
Here is one of our published models held to that standard. ph-eye-pii-en-small
is an English person-name detector, fine-tuned from GLiNER and evaluated on the held-out test split of NVIDIA’s Nemotron-PII dataset, at its recommended confidence threshold of 0.90, on the name label only.
| Matching | Precision | Recall | F1 |
|---|---|---|---|
| Exact span and label | 0.96 | 0.99 | 0.98 |
| Overlapping span and label | 0.97 | 0.99 | 0.98 |
Read the gap rather than the headline. Recall is about 0.99 and precision is about 0.96, and that asymmetry is deliberate. The model is recall-leaning by design, because a missed name is a leak and an extra flag is not. We did not tune it to the prettiest F1; we tuned it to miss as few names as possible and disclosed the precision cost of doing so. The exact and overlap rows differ by a point, which is exactly the kind of detail that disappears when a project reports a single number with no matching rule attached.
One more number that belongs on the card: these results are in-distribution. The model was trained and tested on the same synthetic Nemotron distribution, so they are a ceiling, not a production promise. Accuracy on your real documents will be lower, by an amount that depends on how far your text sits from the training data. The right operating point is the one you pick on a sample of your own documents, not the one in this table. Saying so plainly is part of the report, not a disclaimer bolted on at the end.
These numbers are reproducible with our own open source auditing tool, Philter Scope , which scores any model’s detections against a gold standard and renders the precision, recall, and per-entity breakdown shown below. We walk through exactly how in How We Use Philter Scope to Evaluate Our PII Models , and the training and design decisions behind the model are in How We Built PhEye’s PII Name Models .
The gate, and the part that comes after launch
Two practices keep the numbers honest over time, and both matter more than how many models sit in the catalog.
The first is a release gate. We export each model to ONNX so it can be served efficiently, and the export refuses to publish if the ONNX model disagrees with the original. A model that quietly lost recall during conversion would still show green on every dashboard while leaking names in production, so a divergence aborts the release. We would rather ship nothing than ship a model that is silently worse than the one we evaluated.
The second is re-baselining. A checkpoint that was measured once at launch and never touched again tells you how it did against last year’s assumptions. A model that is re-evaluated as the data, the thresholds, and the failure cases evolve tells you how it does now. A maintained model with a current evaluation is worth more than a larger catalog of artifacts that no one has re-scored since the day they were uploaded.
The bottom line
Do not buy a model catalog by the pound. Ask for one model’s evidence: a held-out evaluation, precision and recall reported separately with the matching rule named, an honest note on where the numbers came from and where they will be lower, and a card an auditor can read. A project that can hand you that for every model it ships is doing the work. A count cannot.
You can hold ours to exactly that standard. The English name models are published on Hugging Face with their numbers and cards: xsmall , small , medium , and large . They are served by PhEye and drop into Philter and Phileas for an end-to-end redaction pipeline you run inside your own boundary.
If you need a model evaluated against your own gold standard, or a custom model trained and proven for a domain or language we do not ship yet, that is work we do .