Precision, Recall, or F1: Which Redaction Metric Matters Most in Your Industry
The most common follow-up question after introducing redaction benchmarking is not “how do I run a benchmark?” It is “what score am I aiming for?” And the answer is not universal. The right target depends entirely on which kind of error is more expensive in your domain: a missed identifier that leaks through, or a falsely redacted word that destroys context.
The table below gives the short answer by industry. The rest of this post explains the reasoning behind each row and shows how to measure and tune toward that target with Philter Scope .
| Industry | Primary metric | Why |
|---|---|---|
| Healthcare (HIPAA, HITECH) | Recall | A single missed identifier is a reportable breach; over-redaction is recoverable |
| Legal and e-discovery | Recall (with auditable precision) | Missed PII in a production costs more than a redaction dispute; privilege review requires traceability |
| Financial services (GLBA, PCI DSS) | Recall for regulated identifiers; Precision for analytical datasets | Account numbers and SSNs must not leak; downstream models degrade on over-redacted training data |
| Marketing, PR, and communications | Precision | Over-redaction makes documents unreadable; missed internal names rarely create compliance exposure |
| Academic and scientific research | F1 | Under-redaction violates ethics-board requirements; over-redaction destroys dataset utility |
| Government and FOIA | Recall (exemptions); Precision (responsive records) | Withholding too much triggers litigation; releasing too much triggers liability |
| Customer support transcripts | Precision | Transcripts are analyzed for product quality and support metrics; over-redaction corrupts analysis |
What these metrics measure in a redaction context
If you are already comfortable with precision and recall, skip ahead. If not, here is the one-paragraph version applied specifically to redaction rather than general classification.
Precision answers: of every token we redacted, how many were actually PII? A precision score of 0.95 means 5% of redactions were false positives: words that were not sensitive but got scrubbed anyway. Low precision produces unreadable documents.
Recall answers: of all the PII that existed in the document, how much did we actually catch? A recall score of 0.95 means 5% of real PII made it through unredacted. Low recall means sensitive data leaked.
F1 is the harmonic mean of the two. It gives a single score that penalizes you equally for being imprecise and for missing identifiers. It is useful when both error types carry similar costs, but misleading when they do not.
The Philter Scope post covers how to produce these numbers against your own data with a command-line tool. This post assumes you have the numbers and focuses on what to do with them.
Healthcare: recall above all else
HIPAA’s Safe Harbor standard lists 18 specific identifier categories. If any one of them appears in a dataset that gets disclosed without authorization, you have a reportable breach. The consequences are severe: OCR investigations, fines, and mandatory notification programs. One missed patient name in a research dataset shared with a university partner can trigger the entire response chain.
The practical implication: healthcare teams should accept lower precision in exchange for higher recall. A transcript where a few non-sensitive date references got redacted is annoying but recoverable. A transcript where a patient name slipped through is a breach notification event.
This is reflected in how HIPAA Safe Harbor is designed. The standard specifies the categories; it does not specify that only and exactly those categories must be redacted. Erring toward caution is expected.
For a full architecture mapping Safe Harbor identifiers to Philter policies, see the HIPAA Safe Harbor blueprint .
Legal and e-discovery: recall with an audit trail
Legal redaction is recall-dominant for similar reasons. A document produced in discovery with a client’s SSN or a patient name in a personal-injury matter is a serious professional liability event. Opposing counsel will notice, and courts have sanctioned parties for less. The risk of under-redaction vastly outweighs the annoyance of a redaction dispute.
The addition that legal work requires beyond raw recall is traceability. Courts and opposing counsel can challenge redactions; you need to be able to demonstrate what was redacted, under what authority, and with what validation. Philter Scope generates a per-document report of what was caught, where, and with what confidence. That report is the artifact that turns “we redacted it” into “we measured and documented the redaction.”
For a detailed breakdown of legal workflows including court filings, e-discovery productions, privilege review, and M&A due diligence rooms, see Redaction for Legal and E-Discovery .
Financial services: it depends on the dataset
Financial services is the most context-dependent entry in the table, because the answer differs between compliance-driven redaction and analytics-driven redaction.
For regulated identifiers (account numbers, SSNs, card numbers under PCI DSS, NPPI under GLBA) the answer looks like healthcare: recall is the priority. These identifiers have a direct mapping to financial harm if exposed. A missed account number in a vendor-shared dataset is a GLBA incident.
For analytical datasets (transaction logs, support transcripts, call recordings being used to train internal models or run product analytics) precision becomes more important. A customer support model trained on transcripts where 30% of tokens are redacted artifacts produces worse outputs than one trained on accurately-redacted, semantically-intact text. Over-redaction degrades the downstream product.
The practical answer for financial-services teams: run two separate policies and two separate Philter Scope evaluations. The compliance policy is tuned for recall; the analytics policy is tuned for the precision-recall trade-off that keeps downstream model quality acceptable.
Marketing, PR, and communications
This is the clearest precision-dominant case. The content in question (press releases, campaign copy, internal communications being cleared for external release, job postings) is not subject to the same regulatory exposure as healthcare or legal work. The names of internal contacts who reviewed a document are not regulated PII. If the redaction engine scrubs those names because they superficially match person-entity patterns, you get an unreadable document without gaining meaningful protection.
Over-redaction in this context is a real operational problem. Comms teams that have experienced it often abandon automated redaction entirely and go back to manual review, which defeats the purpose. Tuning for precision, accepting that a small number of sensitive terms might require manual follow-up, produces a system that people will actually use.
The caveat: if the documents in question do contain regulated identifiers (HR records for a personnel announcement, customer references in a contract excerpt) the recall requirement for those specific entity types still applies. Most communications redaction deployments run a mixed policy: high-precision on names and generic terms, maximum-recall on the small set of structured identifiers (SSNs, email addresses, phone numbers) that carry actual compliance exposure.
Academic and scientific research
Research is the clearest F1 case, and the one where the tension between precision and recall is most explicitly acknowledged. Ethics board approval for sharing a dataset almost always includes a requirement that subject identifiers be removed. Fail to meet it and the dataset cannot be published. Over-remove identifiers and the dataset loses the statistical properties that make it scientifically useful.
The goal is genuine balance, not maximum safety. A de-identified dataset that has been so aggressively redacted that the remaining variables are no longer predictive is a failed experiment, not a successful privacy measure.
F1 is the right optimization target here, but note that F1 hides the direction of error. A 0.92 F1 achieved by trading precision for recall is a different dataset than a 0.92 F1 achieved by the reverse. Research teams should inspect both component scores when evaluating a redaction policy, not just the combined number.
Government and FOIA
FOIA responses exist in a difficult middle: over-redaction is legally challengeable (and the requester will challenge it), while under-redaction can expose protected sources, law enforcement sensitive information, or privacy-act-protected personal information.
In practice, FOIA teams operate with a specific set of statutory exemptions (the nine FOIA exemptions for federal agencies; state-law equivalents vary). The recall requirement applies to those exemption categories. The precision requirement applies everywhere else: redacting beyond what an exemption authorizes creates litigation exposure.
This makes government redaction the most policy-specific case in the table. The entity types requiring near-100% recall are not generic PII categories but specific exemption-mapped terms (law enforcement technique descriptions, source-identifying details, personal privacy information under Exemption 6). Everything outside those categories should be as precise as possible to minimize withholding disputes.
Customer support transcripts
Support transcripts are analyzed for agent performance, product quality signal, and training data for customer-facing AI features. That analysis degrades when the text has been over-redacted. A transcript where “my iPhone screen cracked” becomes “my {REDACTED} screen cracked” is no longer usable for product issue clustering.
The PII present in support transcripts is usually limited to contact information shared incidentally during the conversation (name, email, phone, account number). Philter’s structured detectors handle these with high accuracy and minimal false positives. Running a precision-tuned policy on transcripts, with maximum-recall only on those specific identifiers, produces clean analytical data without leaving contact information exposed.
Measuring and tuning toward your target
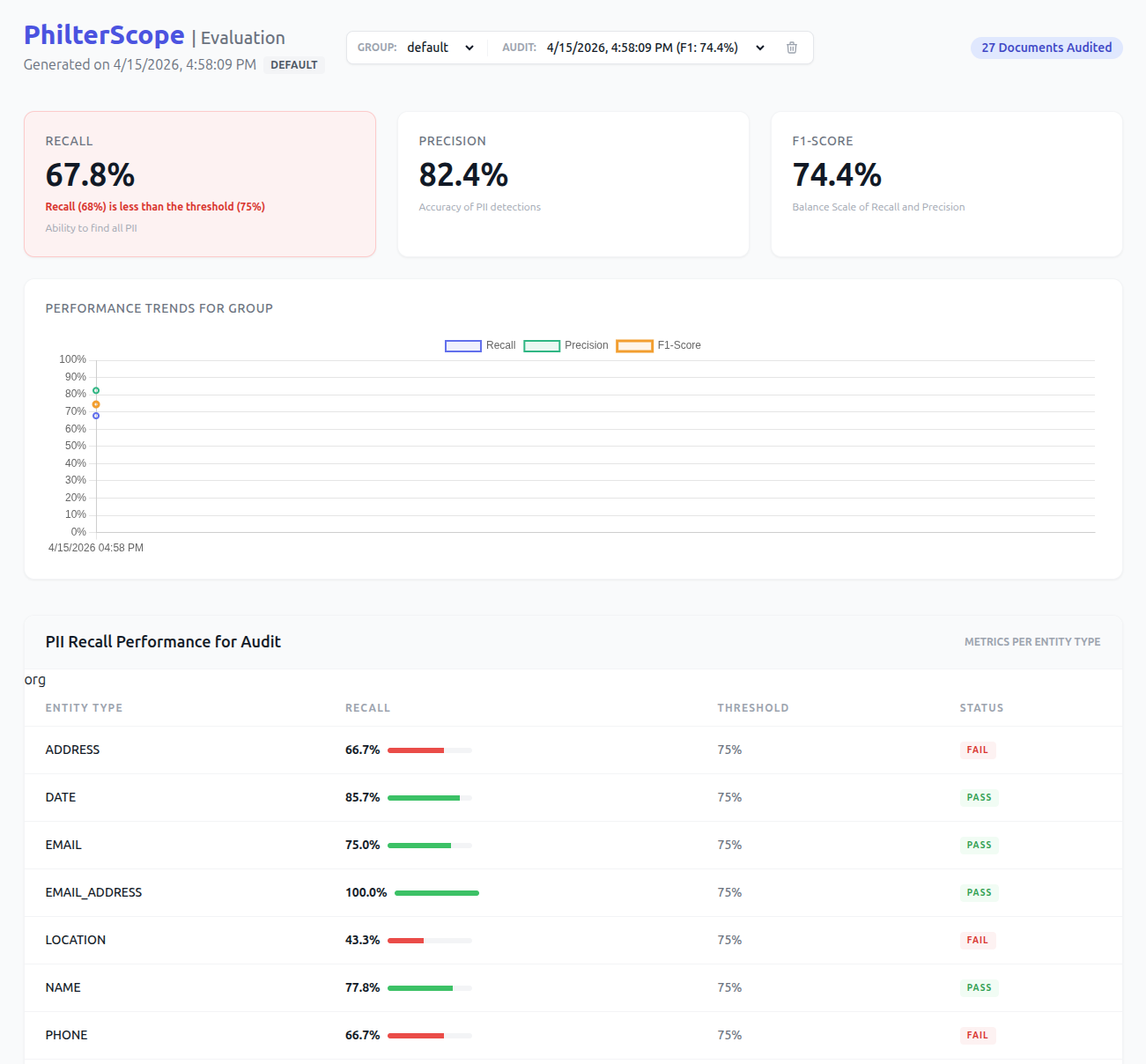
Philter Scope gives you the numbers against real data. Point it at a gold-standard annotated sample and your current redaction output:
$ ./philterscope-audit \
--golden ./examples/golden/ \
--input ./examples/raw/ \
--output ./examples/ \
--threshold 0.90
Precision: 0.887
Recall: 0.963
F1: 0.924
# Full report written to ./examples/report.json
The report breaks scores down by entity type. That per-type breakdown is where tuning starts. A healthcare policy with strong overall recall might show that person-name recall is 0.99 but date recall is 0.82. Dates under HIPAA Safe Harbor are a required identifier category. The overall score looked acceptable; the per-type view reveals the gap that needs to close.
The iteration pattern is: run the evaluation, read the per-type report, adjust the policy (lower the confidence threshold for undercounting entity types, raise it for overcounting ones), re-run, repeat. Philter’s policy files make this loop fast. You are not rewriting code; you are changing configuration parameters and measuring again.
What you need to run this
Philter Scope is open source and available on GitHub . Running an evaluation requires a gold-standard annotated sample of your actual document type. If you are starting from zero, our consulting team can help build that sample and establish baseline metrics before tuning begins.
If you are not sure which metric your organization should be optimizing for, or if you need help mapping your specific regulatory framework to precision and recall targets, get in touch . The mapping from compliance requirement to metric target is one of the first things we work through with new clients, and it shapes every policy decision that follows.