This page walks through what working with us on an AI training-data de-identification engagement actually looks like, from the first call to handoff. It is a representative example to help you picture the work and scope it, not a fixed package. Every engagement is shaped to your corpus, your data types, and the standard you need to meet.
The premise is simple: you have a corpus you want to train or fine-tune on (clinical notes, support transcripts, chat logs, claims data, documents) and you need the PII and PHI removed or pseudonymized before it enters a training pipeline. Everything runs inside your own cloud, so the raw data never leaves your boundary and never comes to us.
When this engagement fits
This is the right engagement if you can describe a corpus and a model you want to train, you have a de-identification standard or compliance driver in mind (for healthcare, HIPAA Safe Harbor or Expert Determination), and you can run software in your own cloud. It is not a fit if you are looking for a managed service that ingests your raw data. Keeping the data inside your perimeter is the whole point, and it is what makes the rest defensible.
How the engagement runs
After the intro call , the work follows the same Discovery, Implementation, and Handoff as any Philterd engagement. Phase 1 below is Discovery. Phases 2 through 4 are what Implementation and Handoff look like for a training corpus. The shape is the same whether the corpus is small or large. What changes is how long each phase takes.
- Discovery. Over a few meetings we map the corpus: data types, formats, volume, languages, and where it lives. We agree on the de-identification standard and on what “good enough” means for your downstream model. You get a detailed assessment of your de-identification needs and an implementation plan, along with a clear success definition. Phases 2 through 4 are that plan being carried out, and you can have your own team carry it out instead.
- Gold-standard and policy design. We build or extend a labeled gold-standard sample from your own data, then author the redaction policy: which entity types, redact versus mask versus pseudonymize per field, and consistency rules so the same subject maps to the same token across documents and the data stays useful for training.
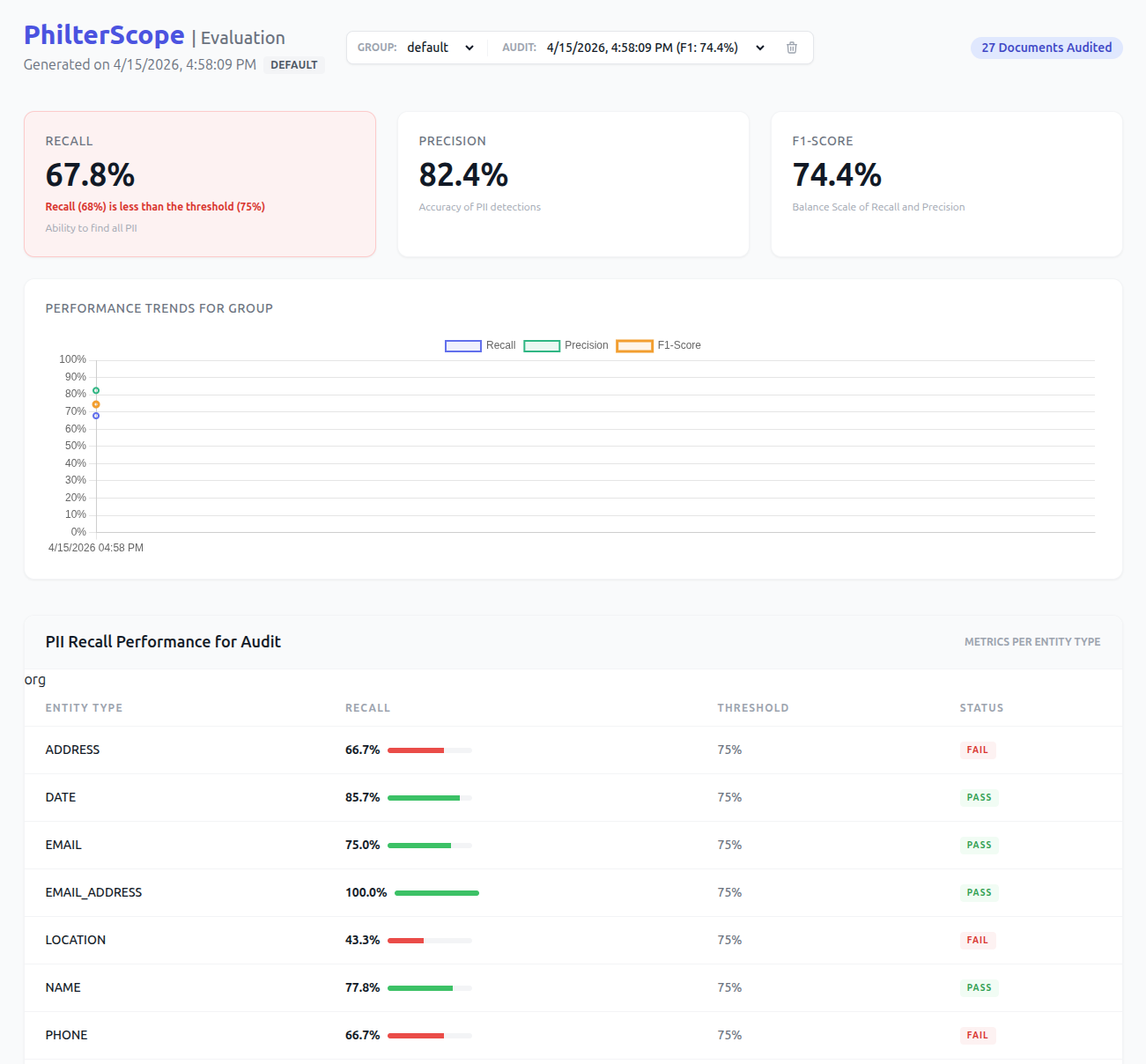
- Tuning and measurement. We run the policy against the gold standard and measure precision and recall with Philter Scope , then iterate until it hits the agreed targets. This is where the engagement earns its value: defensible, measured de-identification rather than a black box. Gray cases can route to human reviewers through Arbiter .
- Production run and handoff. We run the full corpus inside your environment, spot-check the output, and hand off the policy, the pipeline configuration, and the measurement report. If it helps, we wire the redaction step into your training pipeline so re-runs are repeatable.

On timelines: the phases above are deliberately not given fixed durations. How long each one takes depends on the size and messiness of the corpus, the number of data types and languages, the strictness of the standard, and how much human review the gray cases need. We give you a realistic schedule during Discovery, and it can change as the work reveals what the data actually contains.
What you keep
The point of the engagement is that you own the result and can re-run it without us:
- The Discovery assessment and implementation plan, which are yours whether or not we do the build.
- A tuned, documented redaction policy specific to your data.
- A precision and recall report against your gold standard, which is the audit artifact compliance teams ask for.
- A repeatable pipeline that runs inside your environment.
- A short runbook for re-tuning as the data drifts.
How your data is handled
Most of this work happens on a labeled sample and on policy design, which does not require us to hold your full corpus. Philter and the open source toolkit run inside your account, so there is no third-party redaction service to give read access to your training data. Where an engagement genuinely needs us to work against real records, how that data is handled is spelled out in the engagement contract before any work starts. See how we think about data handling in engagements .
Pricing
Engagements are scoped to your corpus and run as a fixed-scope project, with an optional retainer for ongoing corpora or policy maintenance. Because the tooling is the open source stack (Phileas , Philter , Philter Scope , and the gold-standard tooling), there is no per-record data-processing fee. For a number, the best path is the intro call.
This page describes a representative engagement. It is illustrative, not a statement of work, and the actual scope, sequence, and schedule are set with you before work begins.