Redaction feels binary. The data went in, redacted data came out, and a spot check of a few documents looked clean. But redaction is not binary, it is statistical: every policy decides, entity by entity, what to catch and what to let through. The moment you change a rule, add a detector, or adopt a new model, you have placed a bet on thousands of decisions you will never read by hand. "It looked right on a few examples" is a hope, not an audit artifact. You cannot tune what you cannot measure.
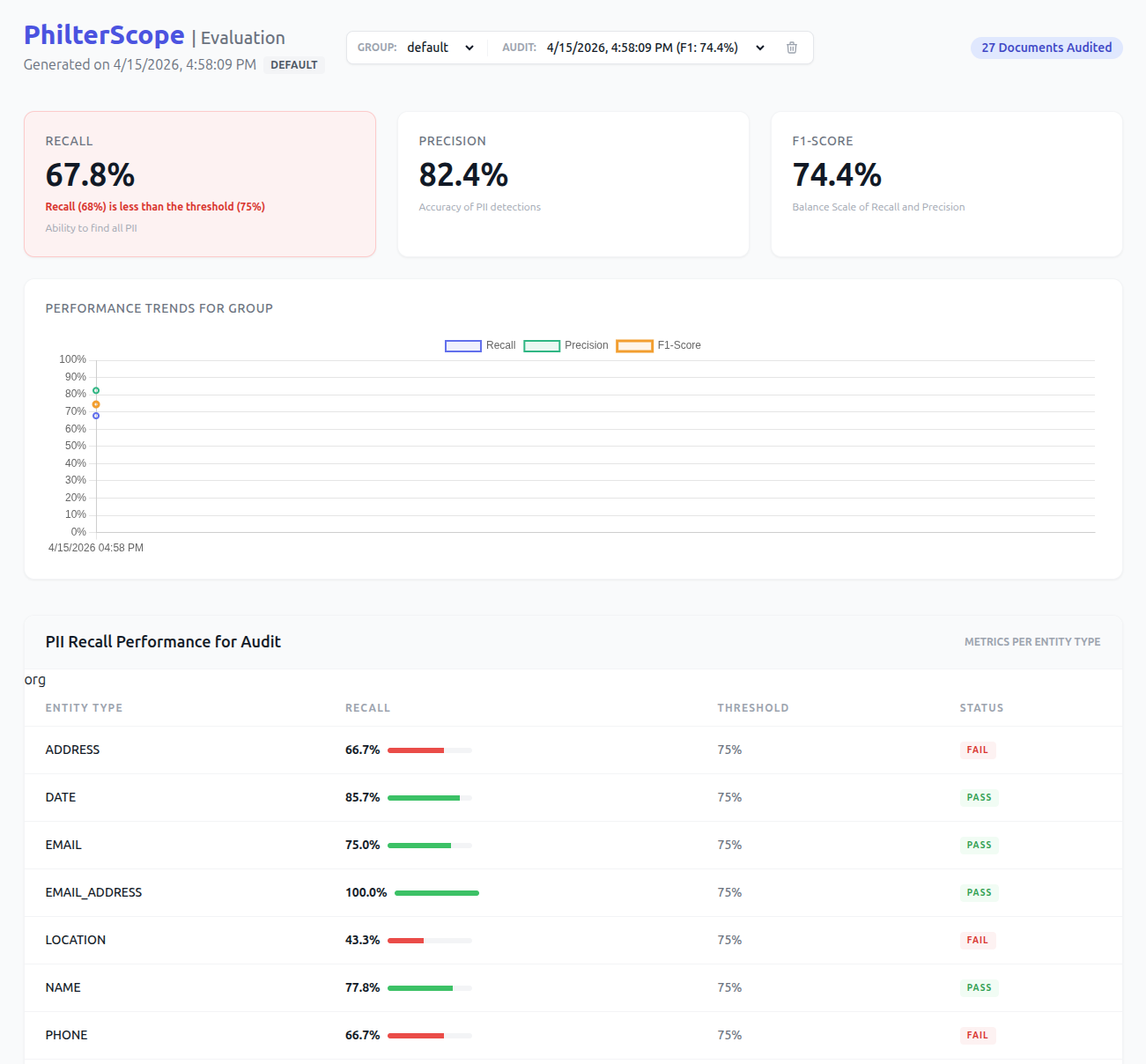
A single headline accuracy number is almost as dangerous as no number at all, because aggregate scores hide exactly the failures that matter. A policy can report 98% overall while quietly missing most medical record numbers or over-redacting the dates your analysts depend on. That is why Philter Scope reports precision, recall, and F1 per entity type against a gold-standard set you annotate once. Precision tells you how much of what you redacted was actually sensitive, so you can see where the policy is destroying useful data. Recall tells you how much of the real PII you caught, so you can see exactly where data is leaking. Per entity, those two numbers turn tuning from guesswork into a targeted decision.
Measurement is what makes a policy safe to change
Policies drift. Models get swapped, input shapes change, and someone tweaks a rule to fix one document. Without a gate, a regression that re-exposes Social Security numbers ships as silently as any other untested change. Scoring a policy in CI turns that risk into a build you can fail: set a floor on recall for the entity types you care about, and a regression is caught before it reaches production, the same way a broken unit test is. The policies you run through Phileas and Philter become something you can version, review, and verify rather than something you hope still works.
Measurement is also what an auditor will accept. "Trust us, it works" is not a control. A reproducible report that scores your real redaction output against ground truth is the evidence regulators actually ask for, and it is the difference between asserting your pipeline is correct and proving it. For a deeper walk through the three metrics and how to read them, see Privacy shouldn't be a guessing game.