We use cookies for analytics and visitor identification to understand how this site is used.
By continuing to browse you accept this use. You can opt out at any time via the
Cookie Settings link in the footer. See our Privacy Policy for details.
Self-hosted PII redaction
Redact PII and PHI. Keep your data yours.
Open source, self-hosted PII and PHI redaction software that runs entirely on your desktop or in your cloud, built for healthcare, finance, legal, and government workloads. Did we mention it's all open source?
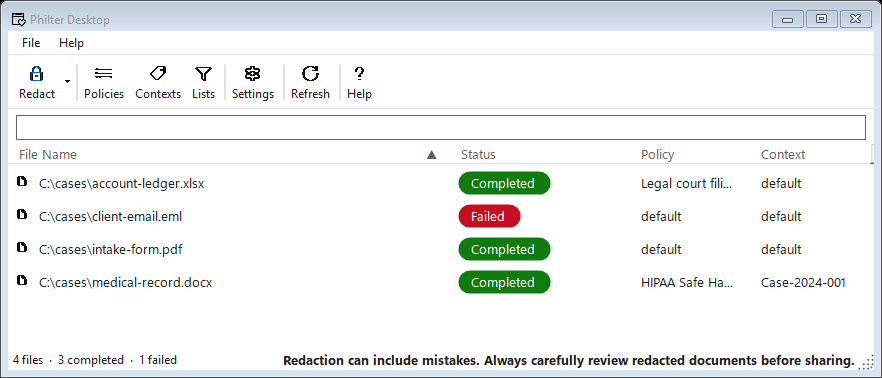
PC-based redaction for small law firms, solo practitioners, and clinics. Redact .txt, .docx, and .pdf files on a single Windows computer, with no server to stand up and nothing sent to a cloud service. Everything runs on your computer.
The turnkey, self-hosted REST API redacts PII and PHI at scale inside your own cloud or data center, built for healthcare, finance, legal, and government text workloads. Call it from your services and it never sends data to a third party.
$ curl http://localhost:8080/api/filter \
--data "His SSN was 123-45-6789." \
-H "Content-type: text/plain"
His SSN was ***********.
Bring in the team that built the software. We assess what you need and deliver an implementation plan, then either build it inside your own cloud and validate it on your data, or hand the plan to your engineers to build. Either way you own the result, and you work directly with the people who wrote the code, not a vendor you renew every year.
We stand up PII redaction in your own cloud, configure and validate it on your data, then hand you a running system you own. No in-house engineering team required. If you would rather build from the Discovery plan yourself, that works too.
Off-the-shelf models miss the identifiers that matter most in your domain. We train specialized PII and PHI detectors on your data, measured against precision and recall you can put in front of an auditor.
Recent blog posts
Practical posts on PII redaction, AI privacy, and self-hosted compliance. View all posts →
OpenAI, Anthropic, Google, and AWS offer PII filtering, but it all runs after your data leaves your network. Why filtering out is not the same as never sending.